Research Paper Dissection - AI Token Inference Attacks

This entire post is based on the research paper by:
Roy Weiss, Daniel Ayzenshteyn, Guy Amit, Yisroel Mirsky
Ben-Gurion University, Israel
Department of Software and Information Systems Engineering
Offensive AI Research Lab
The paper covers two of my current favourite topics (at this time):
- AI (LLM) attack research;
- Encrypted traffic analysis.
Interestingly, they don't really reference ETA (encrypted traffic analysis) in their paper. The fact that they use a "side channel attack" on an encrypted (AI Assistant) data stream - is close enough. They aptly refer to their attack as a "token inference attack".
In this post we will cover the following:
- Most notable - concepts;
- Most notable - findings; &
- All important - so what?
Key concepts
Token
If you have ever investigated to cost structure for ChatGPT API access - you would recall that they charge in terms of tokens (as shown below).

Token structure is better understood using their "tokenizer" (which can be found here). Tokens are a string sequence of characters commonly found in text. The models learn in token sequences - rather than words (like we do). For example, here is my name - passed through the tokenizer application (shown below).
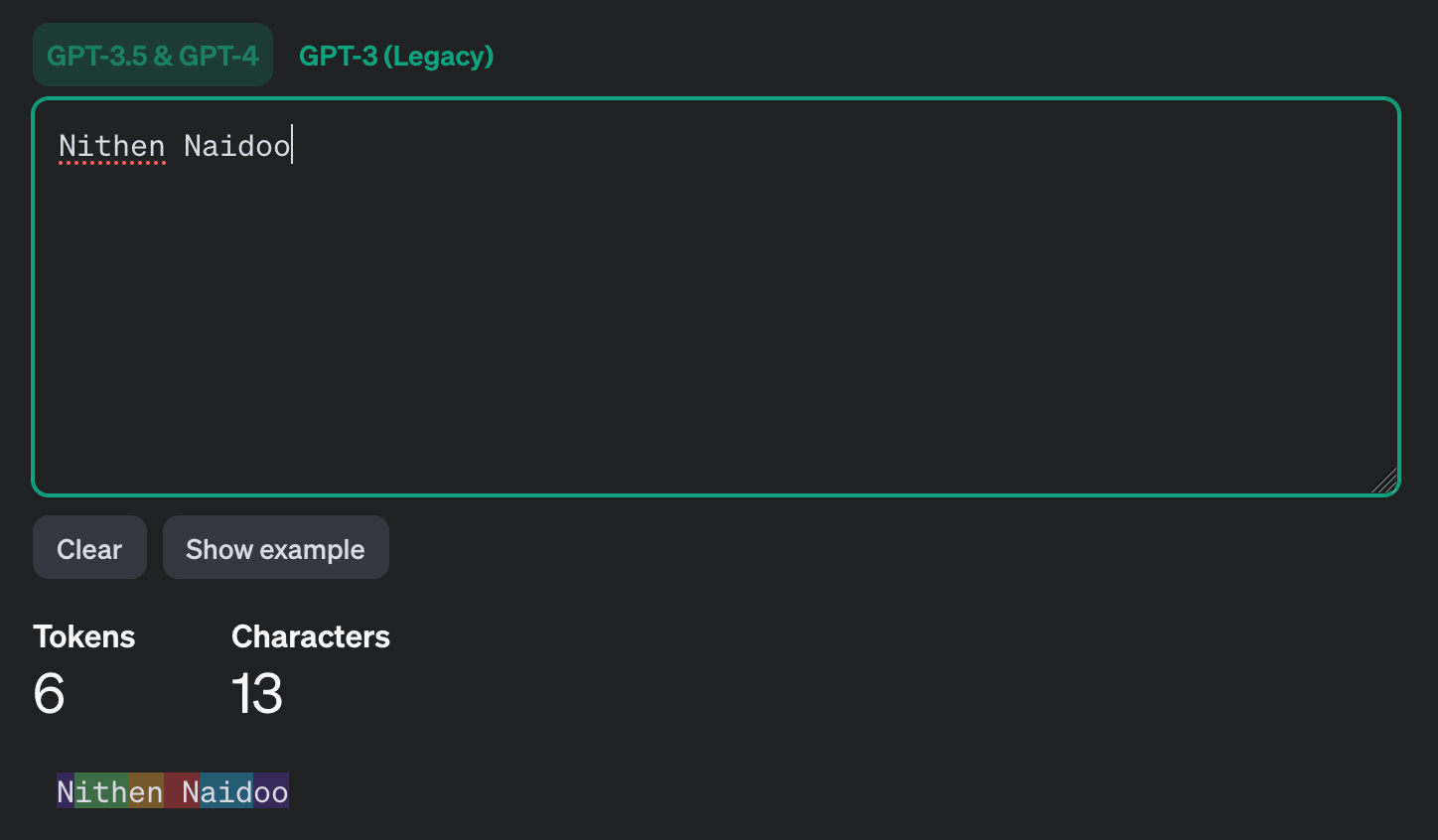
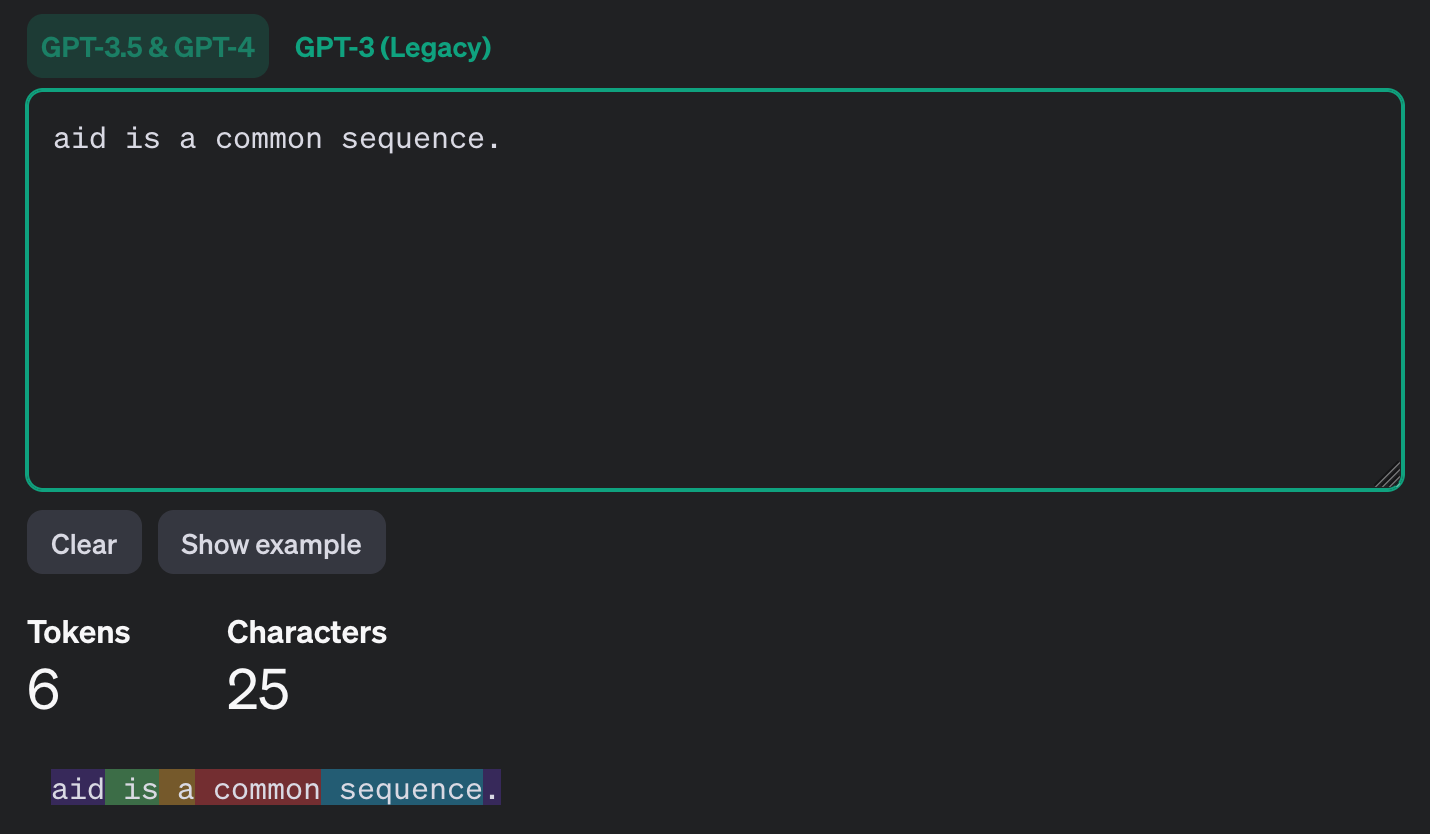
Now, my name is not a common string, but notice how the sequence "aid" appears to be a single token. This makes sense when you think about how tokens are generated.
Inference
Another very cool concept taken from the attack landscape, inference is gaining access to information when we "infer" what the data (value) is with a high degree of certainty.
If I have a Caesar Cipher (where n is the right rotation of the alphabet), which is mathematically represented as:
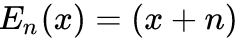
Which simply means plaintext "A" (x=A) is cipher-text "B"; when n=1. So, if we do not know "n", but we have ciphertext "gii", we could infer that n=2 since we know that plaintext "egg" makes sense in context to the encrypted message (omelette recipe).
Attack
For example, threat actor "Wicked Panda" attacking sensitive information and critical computing infrastructure is shown below.

So, now that we have an understanding of (1) Token (2) Inference (3) Attack - let's see what the researchers have found.
Key Findings
Understanding the problem
AI Assistant (chatbots) tend to transmit encrypted messages, without padding, as tokens. So, you can't see the token value - since it's encrypted - but you can see the length. Padding is the appending, prepending or positioning garbage in encrypted messages to prevent disclosure from cryptanalysis. For example, we can predict a prompt response starts with "Certainly, here is an introduction for your topic:" (below).

We now have ciphertext ("gii") that we can position against plaintext ("egg"). Hence, padding will now make such inference impossible. So, now that we understand the problem - let's take a look at an overview of the attack described in the paper.
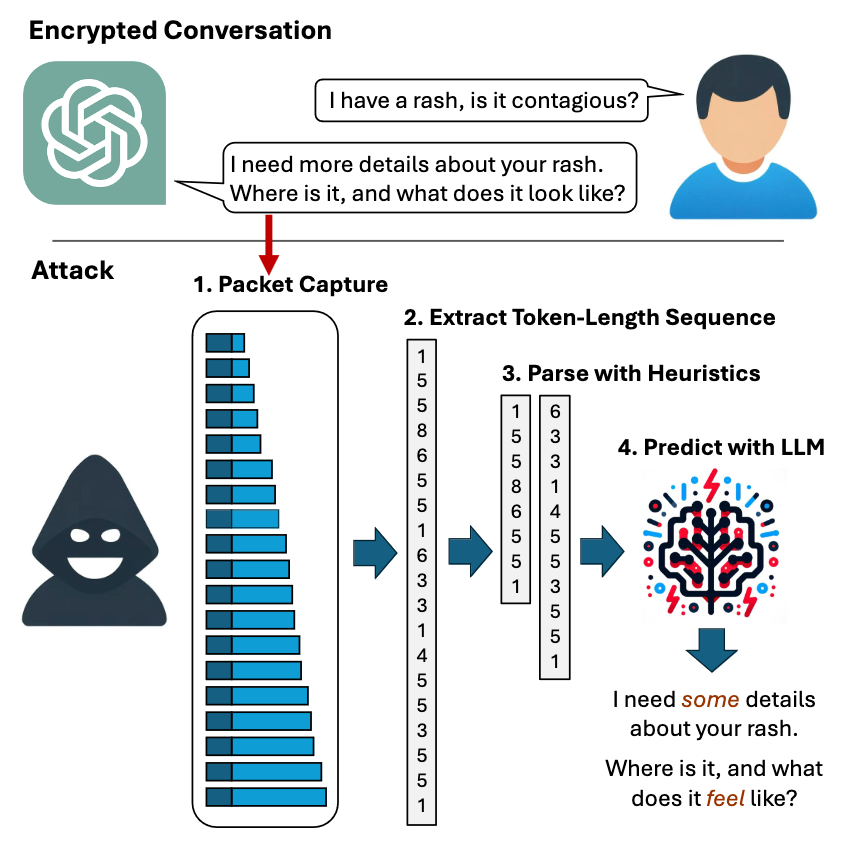
Ooohhh,... the irony! An LLM (large language model) platform is the exact tool that would be really good at predicting what the plaintext equivalent would be. Which is exactly what the researchers used to perform their Token Inference Attack (step 4).
It is important to note that the inferred plaintext is, in most cases, not a perfect match to the original. However, enough of the context is leaked (as shown in the overview).
The solution
As mentioned above, padding would solve the problem. It is my understanding (at the time of writing this post) that most providers have either implemented the fix, or are in the process of remediating.
So what?
There is little to no risk here. The researchers themselves say that a successful attack is highly unlikely. However, this does highlight the need for security in our race to adopt and leverage AI. Additionally, the paper is a great example of the role that offensive research (e.g., AI red team assessment) can play in making your systems more secure.
If you would like more information on AI Red Teaming services contact my team at: Snode Technologies.